Data Science in Academia
The field of Astronomy is unique among the sciences in that astronomers cannot conduct experiments, they can only observe. The observations are made by telescopes which are incredibly expensive to both build and run, and the amount of data coming from these facilities is huge.
My training in Astronomy has given me the ability to identify and apply the most appropriate data science techniques for a specific problem, so that as much scientific information can be extracted from observations as possible, be it in Astronomy or elsewhere.
During my time in Academia, I was interested in and worked on numerous inter-disciplinary projects outside of Astronomy. Here are some examples:
Variation in random capillary blood glucose and HbA1c as predictors of cystic fibrosis related diabetes (CFRD)
The Leeds CF unit implemented electronic care records (ECR) in 2007 coded for all aspect of CF disease. Subjectively, patterns of disease progression have become evident, including increased variation in blood glucose measures prior to diagnosis of CFRD. The aim of this study was to determine objectively whether
- random capillary blood glucose (RCBG) variation and HbA1c differs between those who develop CFRD in the 3 years preceding diagnosis and controls,
- univariate and/or multivariate analysis using longitudinal datasets can predict onset of CFRD
We demonstrated that epidemiological datasets extracted from ECR reveal early potential for prediction of CFRD from multivariate datasets. Multivariate Gaussian mixtures modelling of HbA1c and RCBG show potential as an indicator of CFRD that can be monitored over time, which might be realised with larger sample sizes.
Gaussian process classification of Alzheimer’s disease and mild cognitive impairment from resting-state fMRI
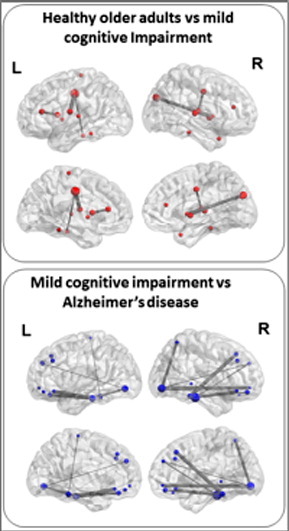
Multivariate pattern analysis and statistical machine learning techniques are attracting increasing interest from the neuroimaging community. Researchers and clinicians are also increasingly interested in the study of functional-connectivity patterns of brains at rest and how these relations might change in conditions like Alzheimer’s disease or clinical depression.
In this study we investigate the efficacy of a specific multivariate statistical machine learning technique to perform patient stratification from functional-connectivity patterns of brains at rest. Whilst the majority of previous approaches to this problem have employed support vector machines (SVMs) we investigate the performance of Bayesian Gaussian process logistic regression (GP-LR) models with linear and non-linear covariance functions. GP-LR models can be interpreted as a Bayesian probabilistic analogue to kernel SVM classifiers. However, GP-LR methods confer a number of benefits over kernel SVMs. Whilst SVMs only return a binary class label prediction, GP-LR, being a probabilistic model, provides a principled estimate of the probability of class membership. Class probability estimates are a measure of the confidence the model has in its predictions, such a confidence score may be extremely useful in the clinical setting. Additionally, if miss-classification costs are not symmetric, thresholds can be set to achieve either strong specificity or sensitivity scores. Since GP-LR models are Bayesian, computationally expensive cross-validation hyper-parameter grid-search methods can be avoided.
We apply these methods to a sample of 77 subjects; 27 with a diagnosis of probable AD, 50 with a diagnosis of a-MCI and a control sample of 39. All subjects underwent a MRI examination at 3 T to obtain a 7 minute and 20 second resting state scan. Our results support the hypothesis that GP-LR models can be effective at performing patient stratification: the implemented model achieves 75% accuracy disambiguating healthy subjects from subjects with amnesic mild cognitive impairment and 97% accuracy disambiguating amnesic mild cognitive impairment subjects from those with Alzheimer’s disease, accuracies are estimated using a held-out test set. Both results are significant at the 1% level.
Creating longitudinal datasets and cleaning existing data identifiers in a cystic fibrosis registry using a novel Bayesian probabilistic approach from astronomy
Patient registry data are commonly collected as annual snapshots that need to be amalgamated to understand the longitudinal progress of each patient. However, patient identifiers can either change or may not be available for legal reasons when longitudinal data are collated from patients living in different countries. Here, we apply astronomical statistical matching techniques to link individual patient records that can be used where identifiers are absent or to validate uncertain identifiers. We adopt a Bayesian model framework used for probabilistically linking records in astronomy. We adapt this and validate it across blinded, annually collected data. This is a high-quality (Danish) sub-set of data held in the European Cystic Fibrosis Society Patient Registry (ECFSPR). Our initial experiments achieved a precision of 0.990 at a recall value of 0.987. However, detailed investigation of the discrepancies uncovered typing errors in 27 of the identifiers in the original Danish sub-set. After fixing these errors to create a new gold standard our algorithm correctly linked individual records across years achieving a precision of 0.997 at a recall value of 0.987 without recourse to identifiers. Our Bayesian framework provides the probability of whether a pair of records belong to the same patient. Unlike other record linkage approaches, our algorithm can also use physical models, such as body mass index curves, as prior information for record linkage. We have shown our framework can create longitudinal samples where none existed and validate pre-existing patient identifiers. We have demonstrated that in this specific case this automated approach is better than the existing identifiers.